How to provision persistent volume in Kubernetes¶
20 September 2018¶

I recently got the chance to speak at DevoxxFR. I loved the event, and even more the chat I had in the hallway track. I went there to talk about the different ways of managing stateful applications via Kubernetes, this talk raised a lot of questions which inspired me to write this blog post.
Most of this questions were about the persistent volume provisioning, so let's dive into this subject.
The 2 ways of managing it:
Manually creating the persistent volume, which is leading to you creating all the persistent volume on your own (the last thing you want to do)Automatically creating the persistent volumeby letting Kubernetes talk with your storage backend so that it can provision itself what it needs
If you do not know what is a persistent volume, that's ok . Let say that you can see it as a network disk or a network drive, whatever rings a bell in your mind.
Some would argue that there is also the statefulset object and I would answer that from a state perspective the statefulset is using the automatic creation of the persistent volume, nothing more. Hoever statefulset are providing a number of feature usually useful when dealing with stateful applications. The most useful one, in my opinion, being the ordered deployment and deletion of pods.
Let set some context¶
To make it easier to understand, let put some context here. Let's say that we are in a company called BigCo. BigCo has already rolled out Kubernetes to manage all services it provides. John and Bob are 2 employees of BigCo. John is a sysadmin and Bob is a developer. One day Bob come to John with an ask, he would need to run a MySQL database in the Kubernetes cluster hosting his application.
Manually creating the persistent volumes¶
After some research John is ready to share a small POC with Bob. John just want to validate the concept, therefore he choose to create the persistent manually himself and don't get into the automatic persistent volume creation.
The flow¶
So here is how the provisioning process work in this situation:
1.BigCo has a Kubernetes cluster and a storage backend up and running. They can both communicate together:
 2.
2.John create a persistent volume:
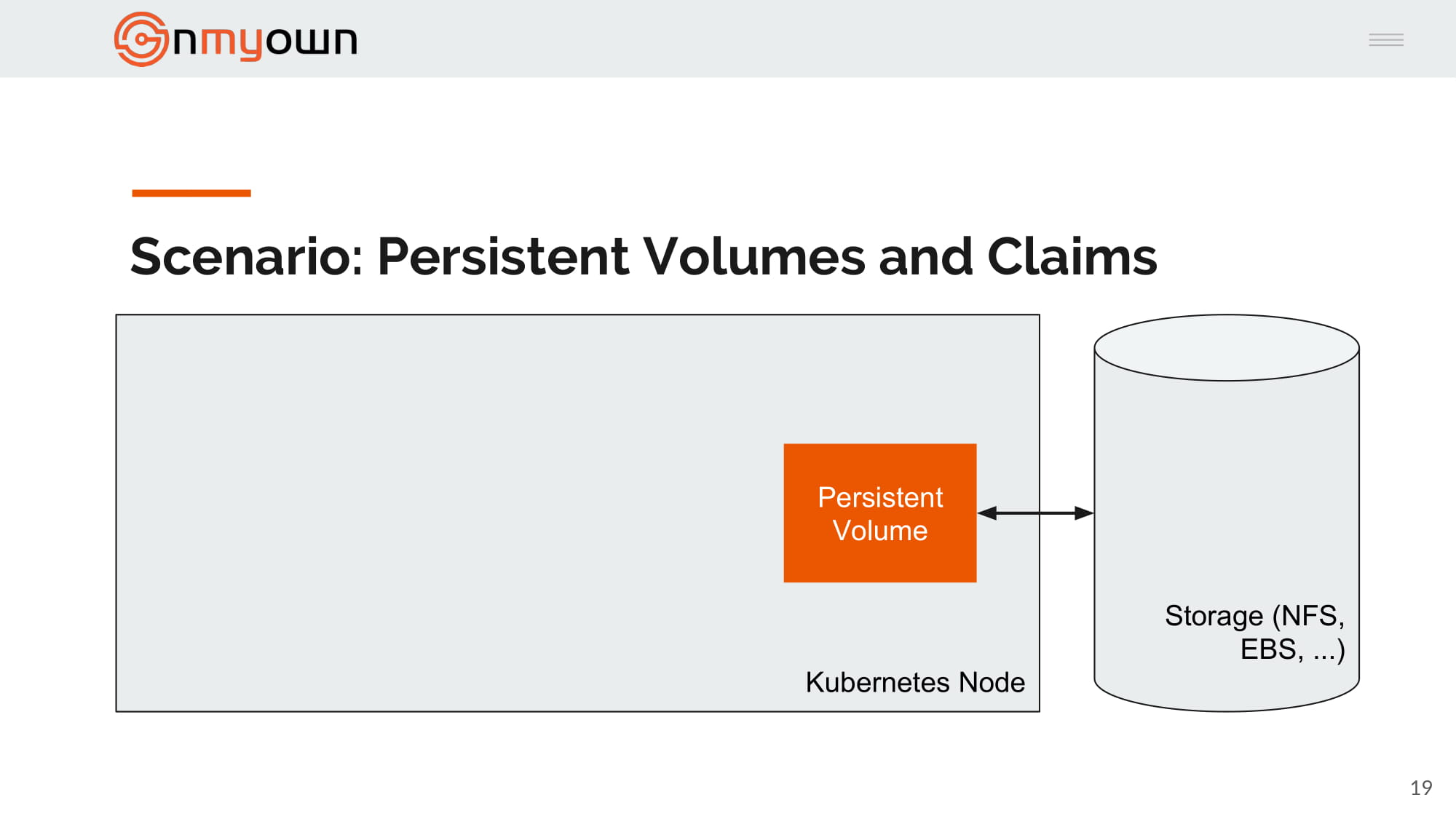 3.
3.Bob create a persistent volume claim referencing the persistent volume previously created:
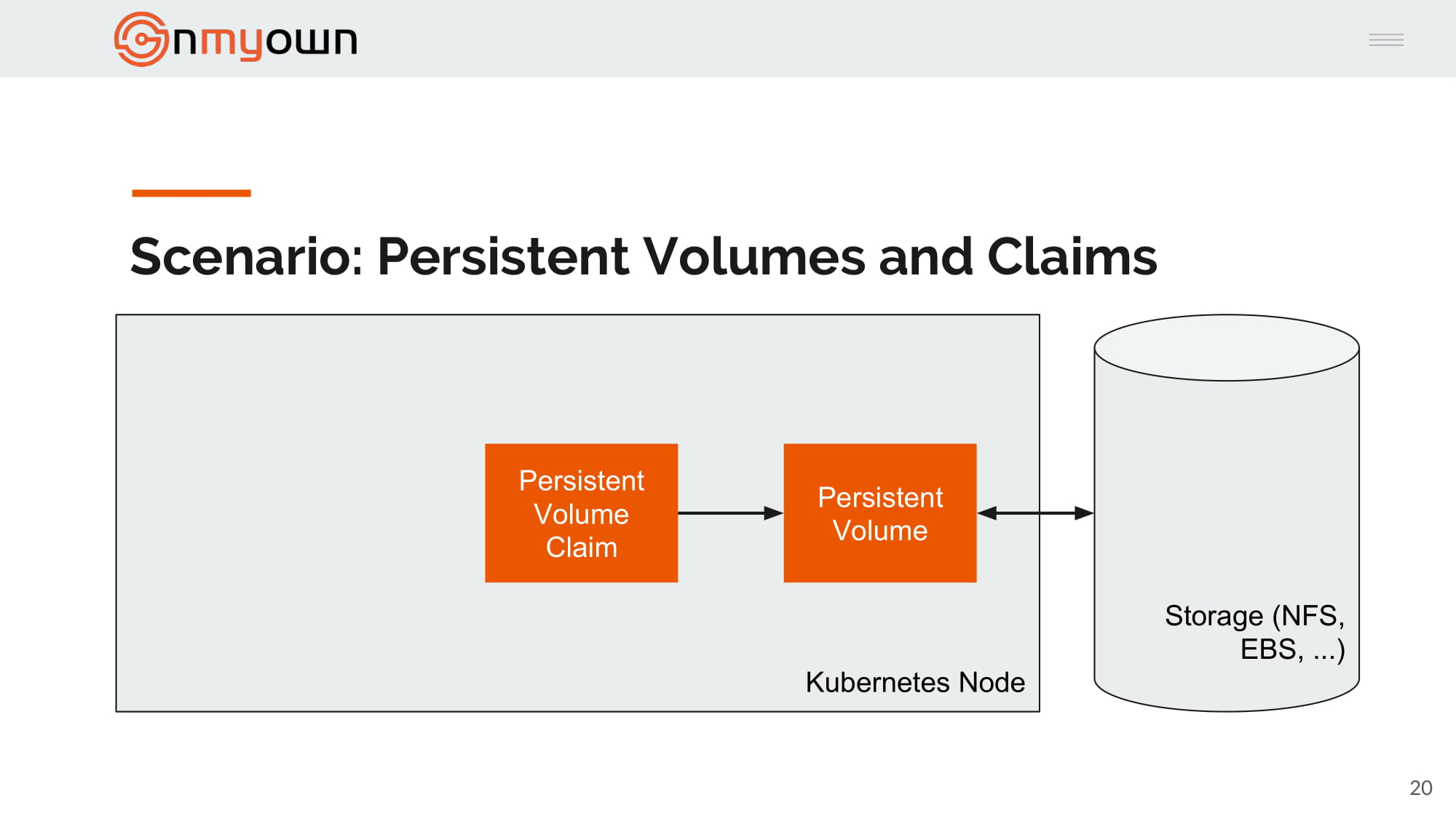 4.
4.Bob create a pod and reference the persistent volume claim in this pod:
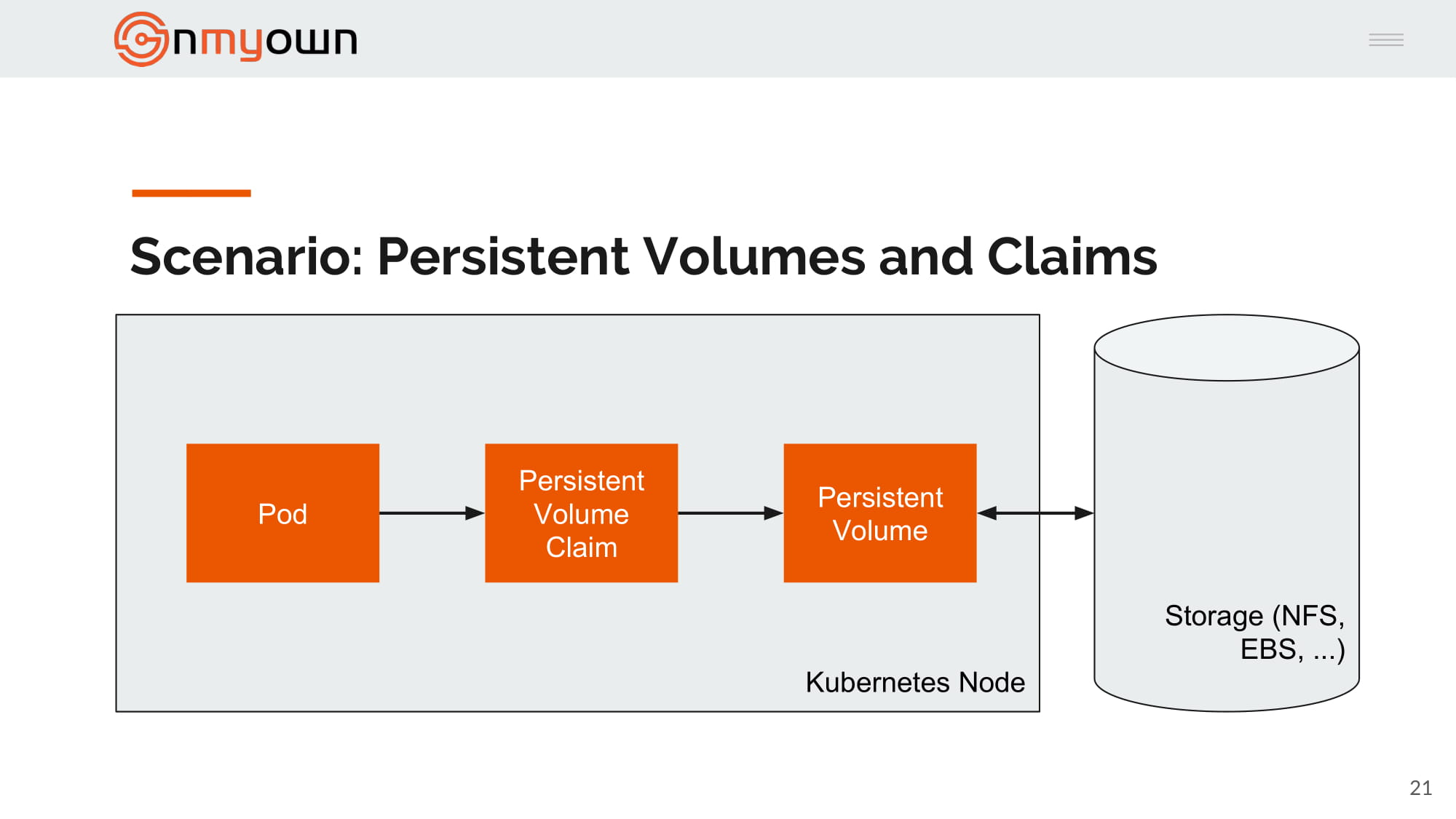 5.
5.Kubernetes mount the persistent volume in the pod:
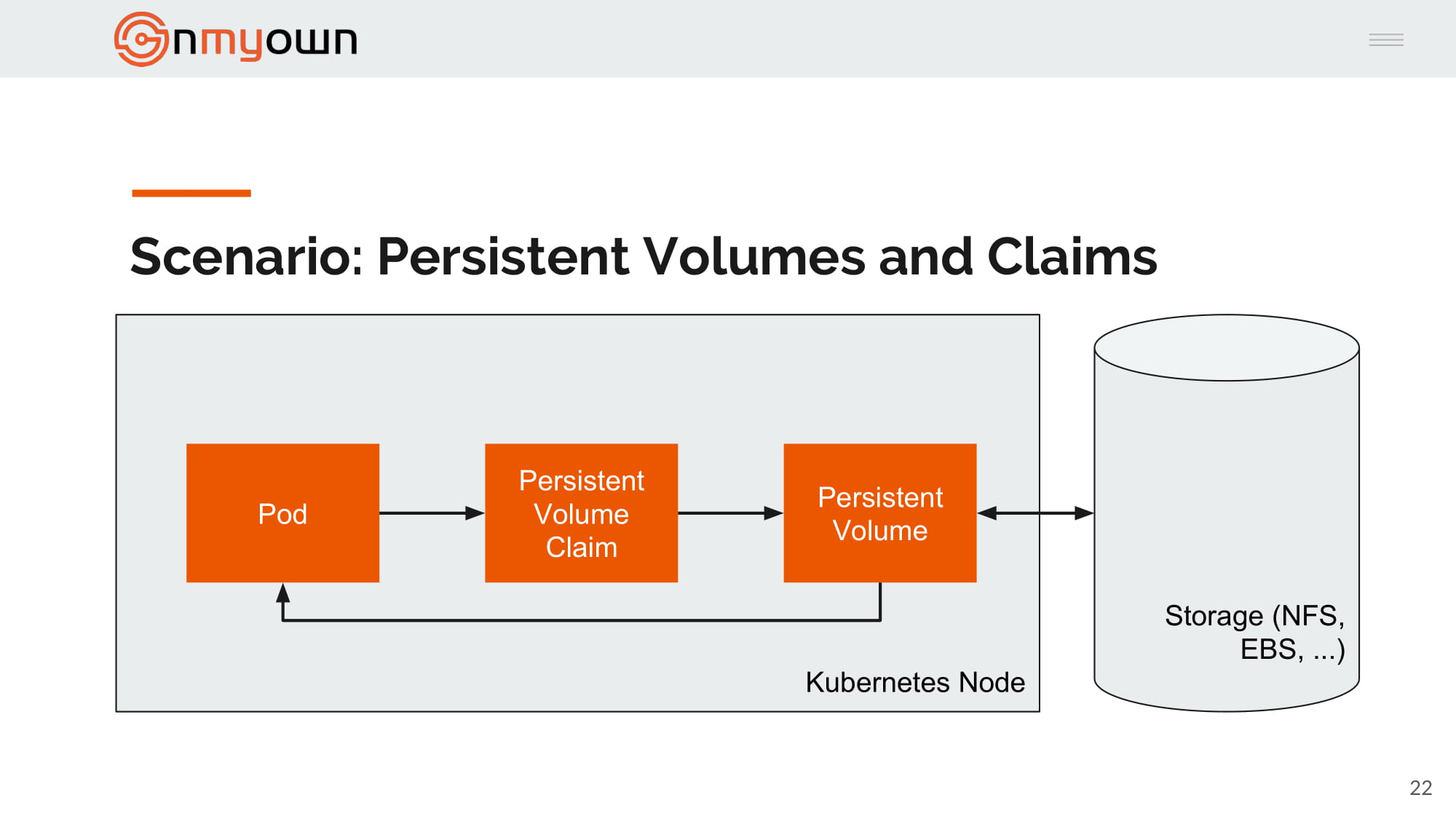
The code¶
Tested on Minikube, if you are not running Minikube, there will some minor change to do, mainly in the persistent volume description.
1.Deploy a namespace (that's always the first thing to do):
1 2 3 4 | |
persistent volume:
1 2 3 4 5 6 7 8 9 10 11 12 | |
persistent volume claim:
1 2 3 4 5 6 7 8 9 10 11 12 | |
pod. Here we will be deploying it using a deployment object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | |
service:
1 2 3 4 5 6 7 8 9 10 11 | |
Kubernetes cluster using this command:
1 | |
The result¶
Now if the pod dies and is rescheduled somewhere else, the data will not be lost.
Limitation¶
John had to create a persistent volume before Bob could do his job, in BigCo, that is usually meaning the Bob had to submit a ticket to John. Which is usually source of slowdown in the process, which we want to avoid.
Automatically creating the persistent volumes¶
As Bob is happy with the solution proposed by John, he wants spin up more instances. John quickly need to industrialize the process and after some additional research, he put in place the automatique creation of the persistent volume.
The flow¶
So here is how the provisioning process work in this situation:
1.Again, BigCo has a Kubernetes cluster and a storage backend up and running. They can both communicate together:
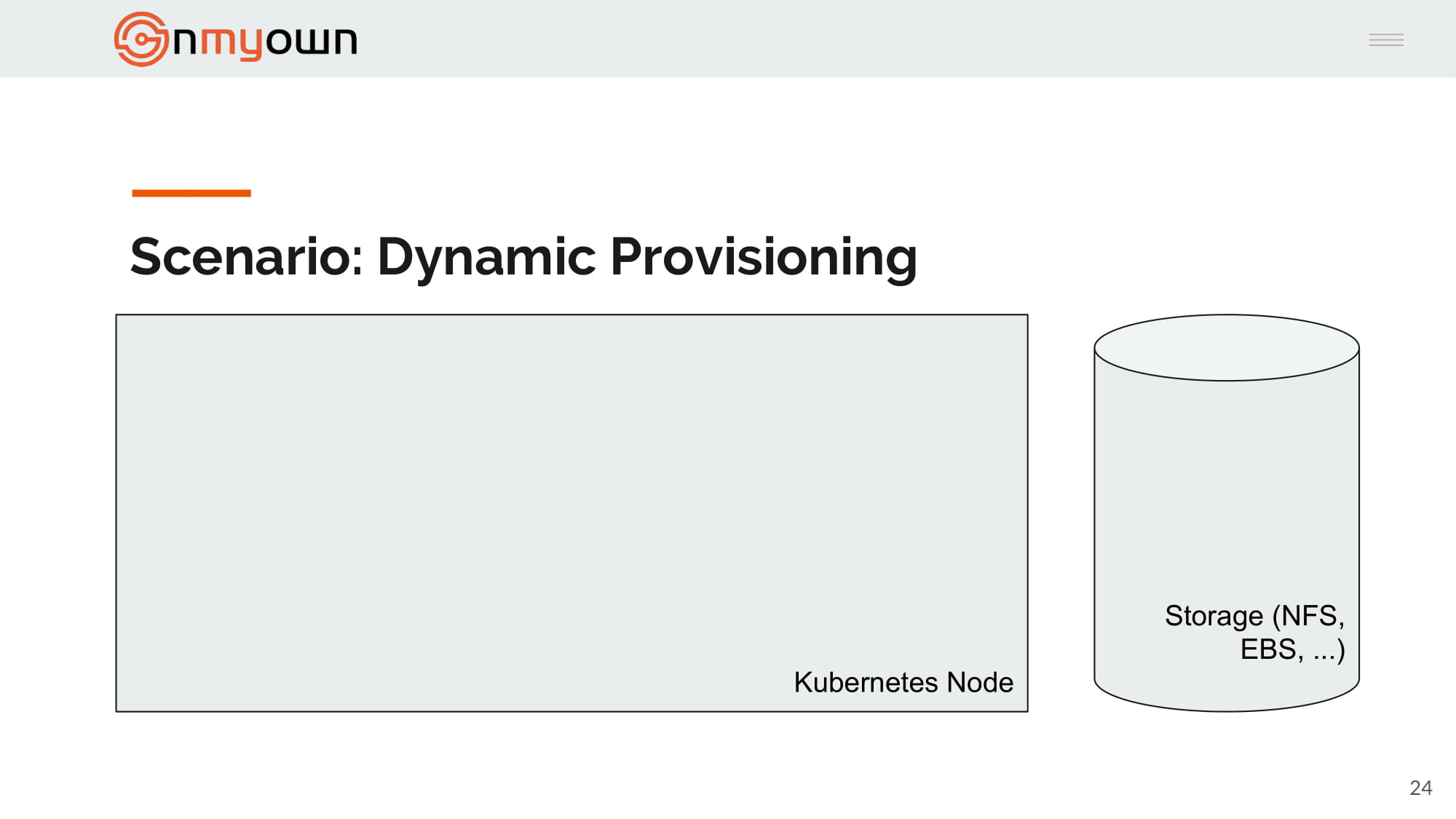 2.
2.John create one or many storage class, you can see storage class as type of storage (SSD, HDD, ...):
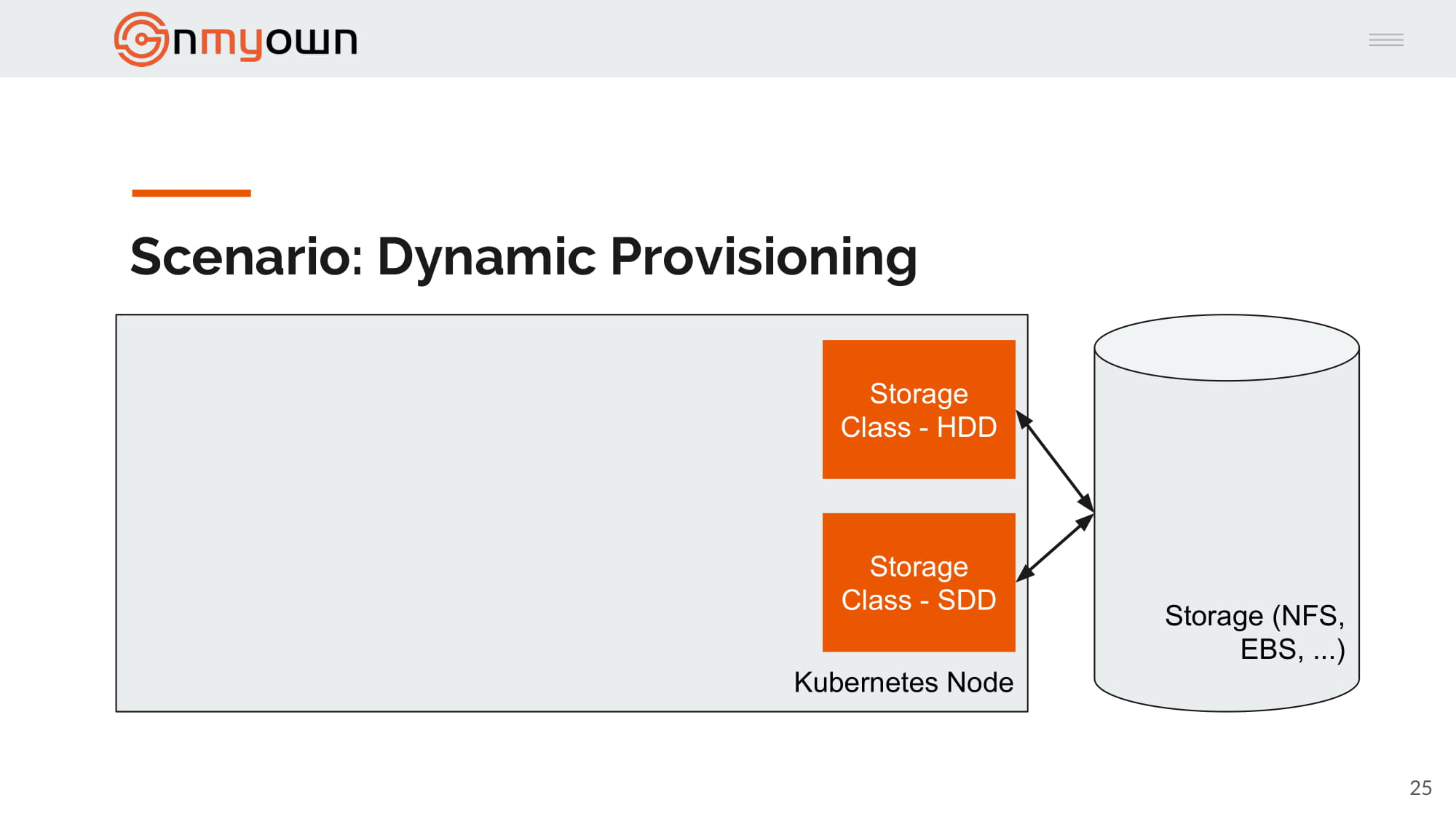 3.
3.Bob create a persistent volume claim referring this time to one of the storage class:
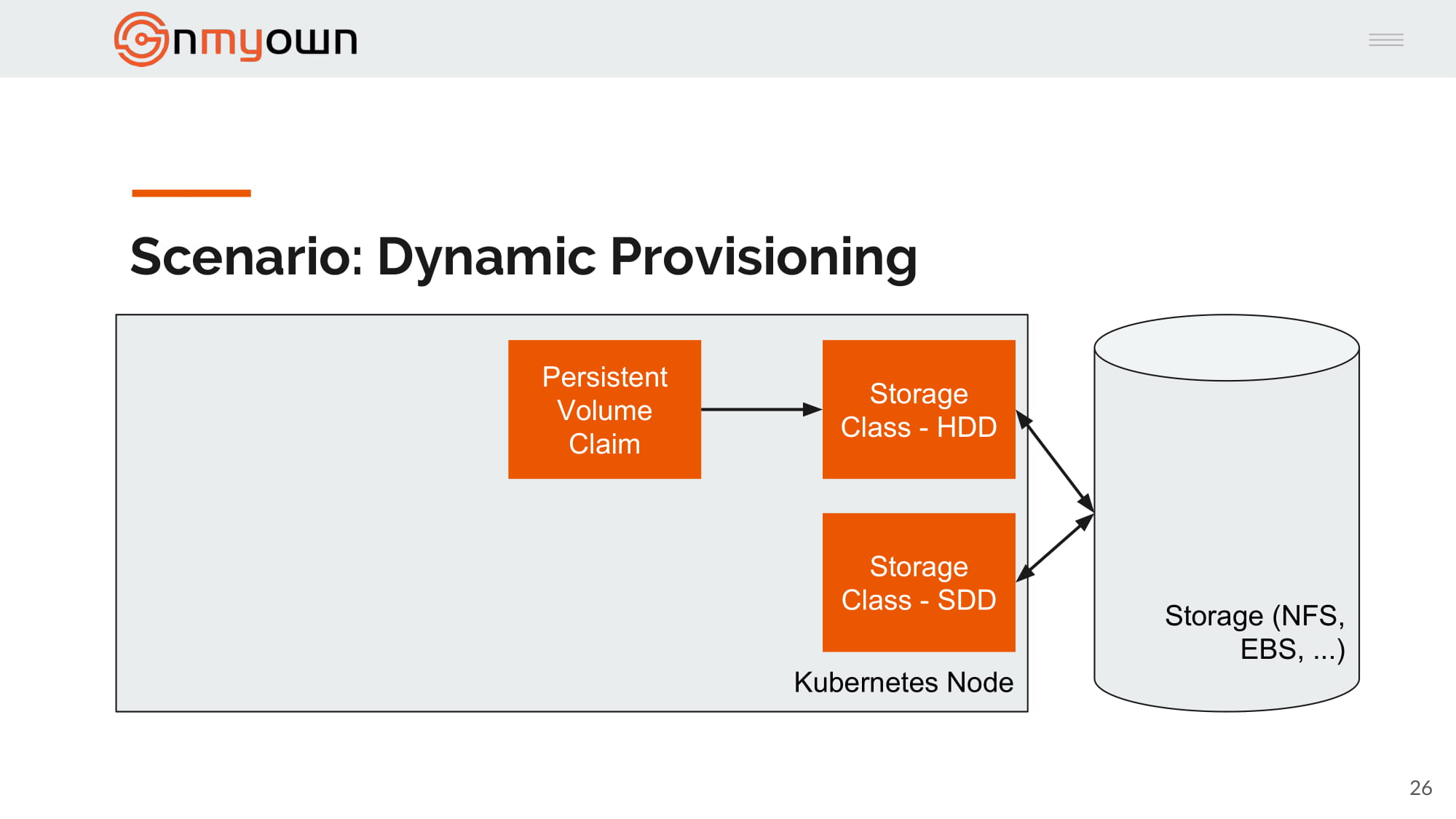 4.
4.Kubernetes create the persistent volume based on the persistent volume claim and the storage class chosen:
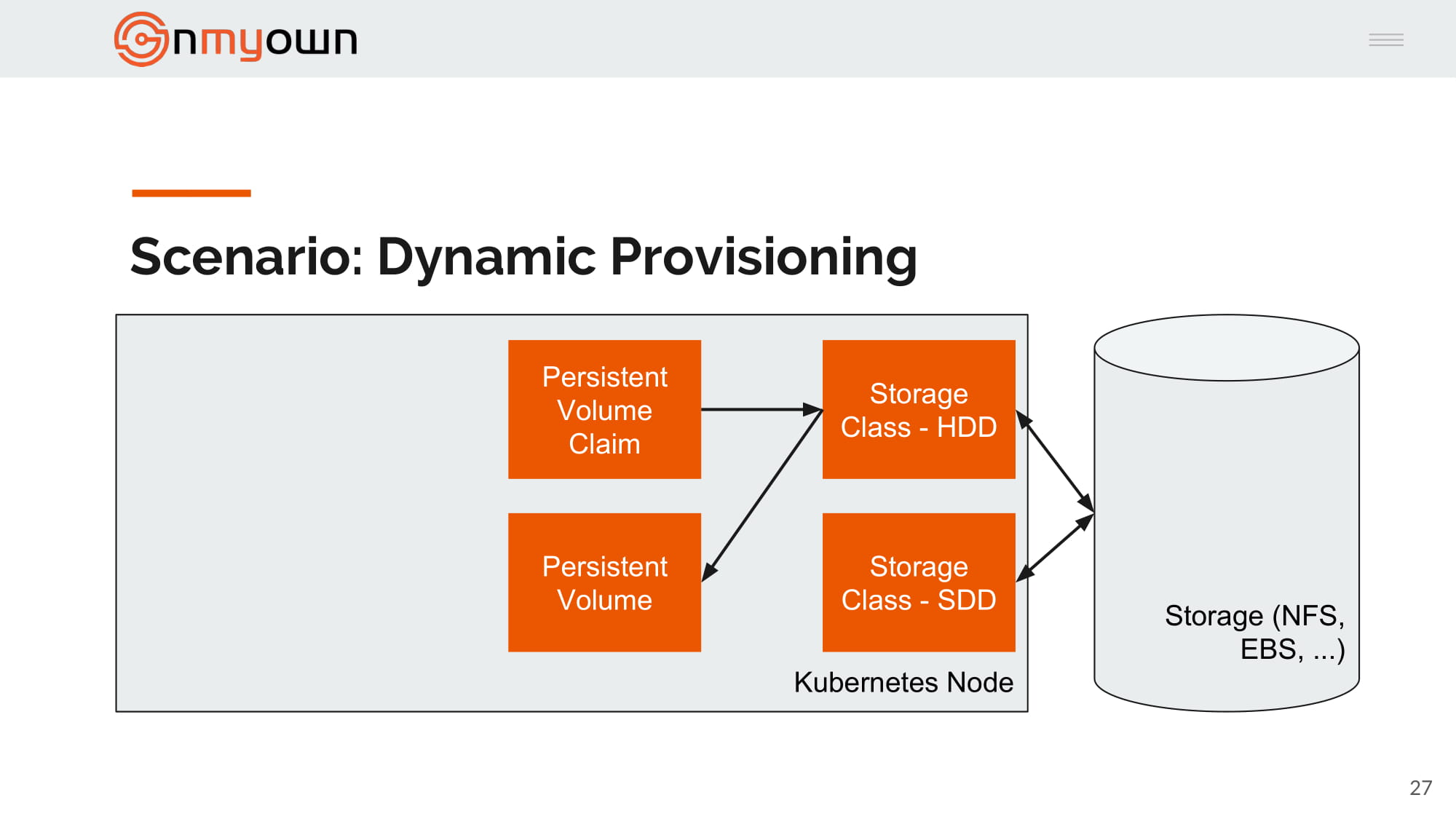 5.
5.Bob create a pod and reference the persistent volume claim in the pod:
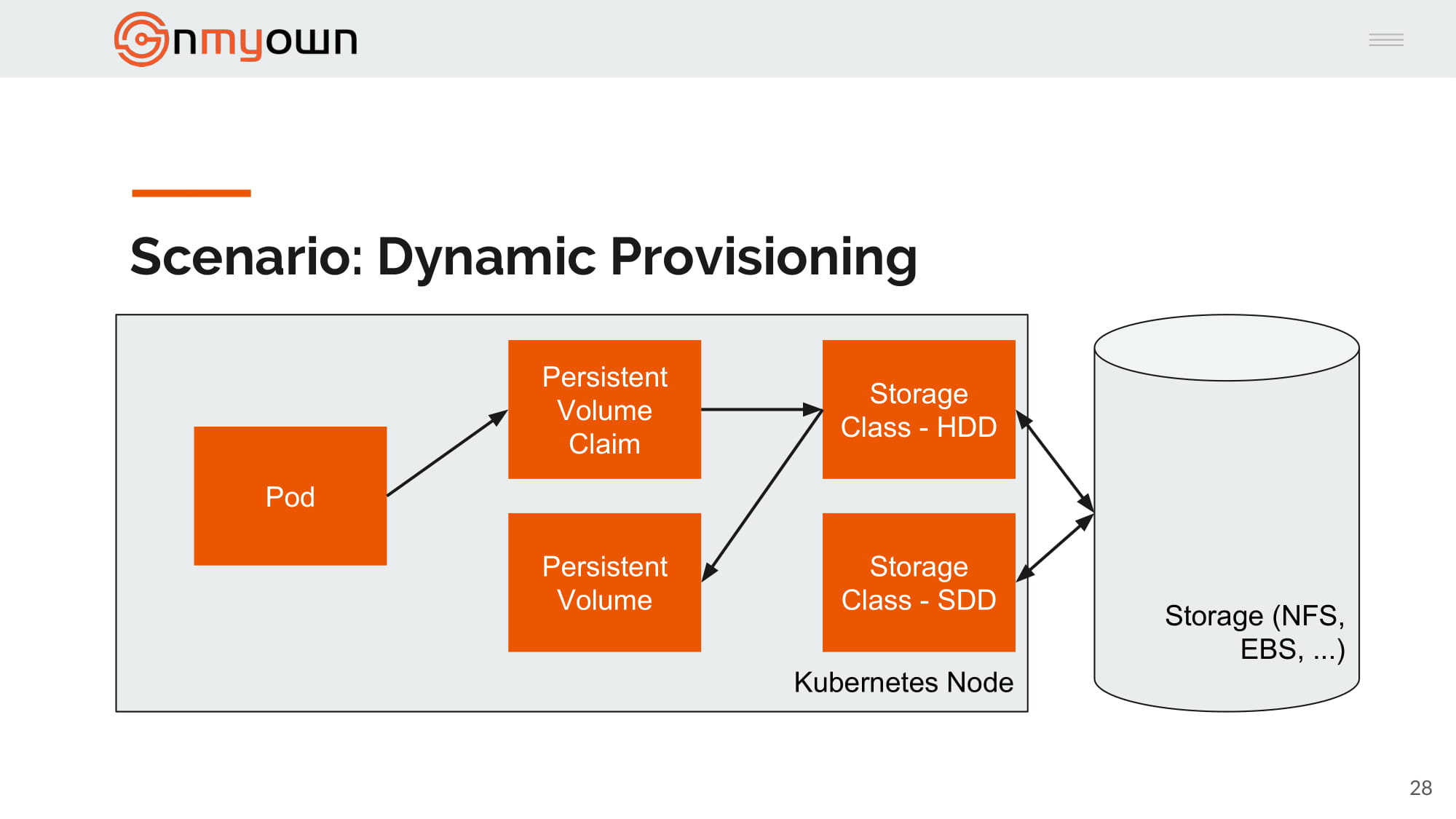 6.
6.Kubernetes mount the persistent volume in the pod:
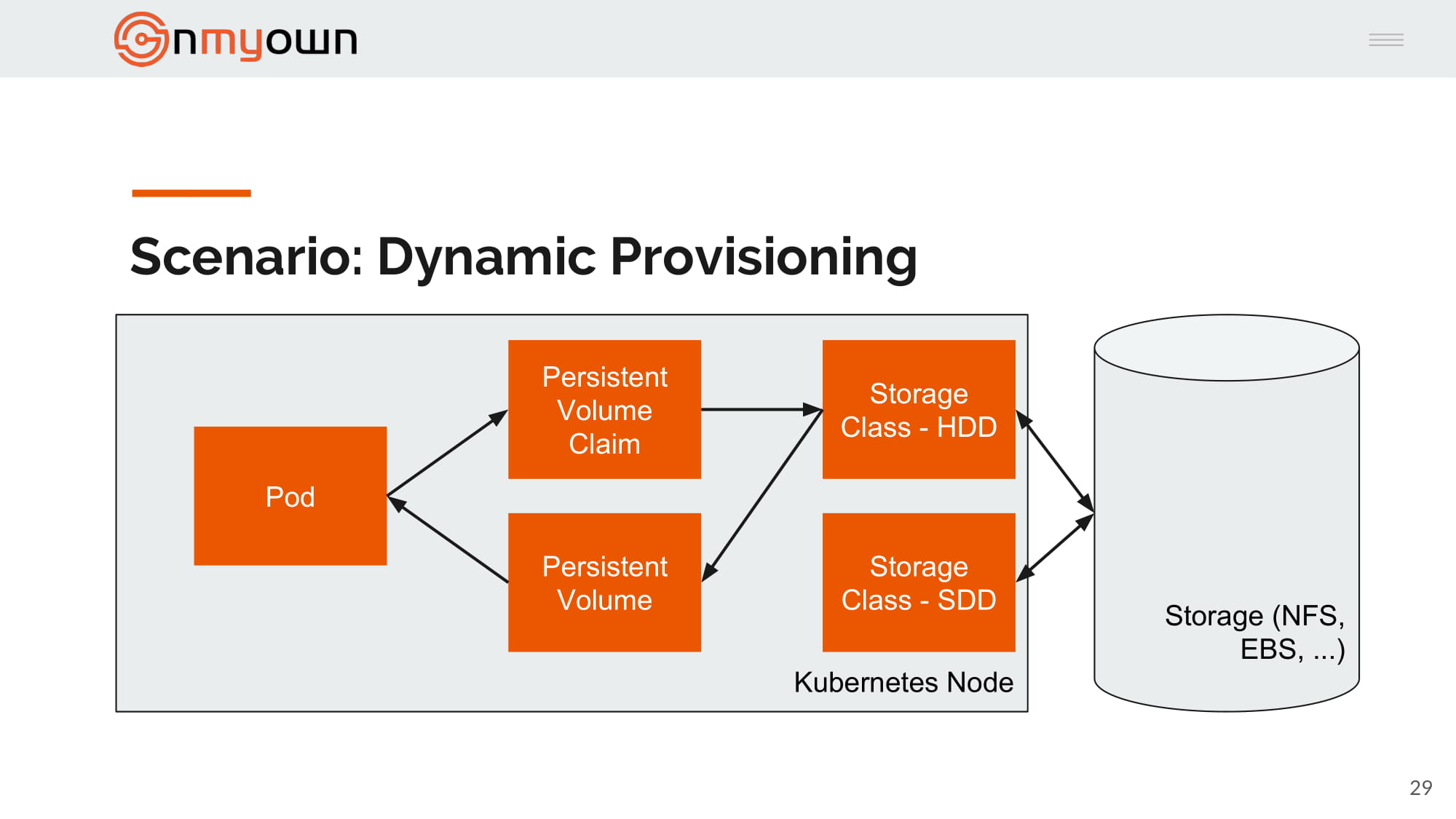
The code¶
Here again tested on Minikube. Should also work on other Kubernetes cluster with minor changes to the storage class.
1.Deploy 2 storage class:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
namespace:
1 2 3 4 | |
persistent volume claim:
1 2 3 4 5 6 7 8 9 10 11 12 | |
pod, again using a deployment object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | |
service:
1 2 3 4 5 6 7 8 9 10 11 | |
Kubernetes cluster using this command:
1 | |
The result¶
Same thing as previously, if the pod dies and is rescheduled somewhere else, the data will not be lost.
We even reused a lot of the code, basically, the biggest changes are the storage class introduction and the fact that the persistent volume claim is now referencing to the storage class instead of the persistent volume.
Additionally, once the many storage class have been created by John, Bob can create without delay the persistent volume he need.
Limitation¶
As persistent volume are dynamically created, some people tend to forget to manage the all lifecycle, which can lead to persistent volume not deleted even if they are not used anymore. However, this can be easily worked around by reviewing from time to time the list of persistent volume instantiated and not linked to a pod.
Conclusion¶
To sum up everything, use the automated way, as always. And if you want to manage stateful app on top of Kubernetes, Statefulset is worth a look.